State machine and async queue (French)
[2023-02-07] #Design_pattern #State_machine #Code
Machines à états (première partie)
Multithreading, atomicité et files non-bloquantes
Introduction
Dans sa carrière, un bon informaticien qui tentera d’implémenter un programme cherchera à le présenter d’une façon plus abstraite. Penser l’architecture d’un programme est une phase importante de son développement. Une des méthodes d’architecture consiste à imaginer son programme comme une machine à états. Car c’est toujours possible. Cette méthode de représentation est vieille comme l’informatique. Aujourd’hui, elle est mise en avant par des frameworks tels que React et Redux. Mais il n’est pas nécessaire d’utiliser un framework pour qu’un programme ressemble à une machine à états.
Je découperai mon travail en trois parties, et les prochains chapitres en couvriront la première. Chacune d’entre elles aura un focus précis sur des mécanismes disponibles en informatique et j’utiliserai l’implémentation de machines à états comme prétexte pour parler de ces derniers. Cette partie sera consacrée aux files d’événements qui modifient ces automates. Dans ce contexte, les files d’événements doivent être traitées de façon séquentielle, elles représentent donc des goulots d’étranglement pour les performances d’un programme. Je ne dis pas qu’il soit effectivement important de se soucier autant des performances d’un automate. Cependant, traiter ce sujet offre l’occasion de regarder de plus près ce qui peut être utilisé dans un programme multithreadé. Je ne peux pas non plus dire dans quels contextes ces mécanismes sont réellement appliqués, ils n’en restent pas moins intéressants. Mais ils existent et sont utilisés, pour des raisons parfois arbitraires, à cause de croyances personnelles, ou bien plus raisonnablement, du fait des connaissances poussées du sujet. Parfois, plus simplement, ils sont présents parce qu’un sous-problème nécessite une attention particulière et doit être le plus performant possible, on essaie donc plusieurs méthodes, souvent empiriquement. Si j’échoue à faire comprendre pour quelles raisons une machine à états correspond à votre cas d’usage, ces chapitres pourront être intéressants au moins pour les sujets variés qu’ils abordent.
Je ne présenterai donc pas tout à fait, comme pourrait l’indiquer le titre trompeur, les machines à états. Cependant, pour le contexte j’évoquerai tout de même une introduction sur l’état de l’art aujourd’hui. J’y ajouterai quelques opinions personnelles, également partagées par quelques collègues et amis, bien que subjectives. Pour l’introduction, j’utiliserai un langage qui est habituellement plus adapté pour parler de parseurs (analyseurs syntaxique). Même si un analyseur est un sous-type de machine à états, le vocabulaire sera suffisant. Je parlerai donc de grammaires, de contextes, de conflits, etc.
Un chapitre sur deux en moyenne sera dédié au multithreading, aux structures de données non-bloquantes. En particulier des files d’attente, des implémentations de mpsc (Multiple Producer Single Consumer), d’opérations atomiques et de mécanismes de synchronisation. Ce sujet est bien plus complexe qu’il ne le paraît. Changer une structure synchrone en une structure non-bloquante asynchrone n’est pas anodin et peut avoir un fort impacte sur un programme. Parfois, l’espace mémoire que la structure prendra sera bien plus grand que l’original. Parfois, il faudra faire des concessions sur les performances et se poser les bonnes questions.
Quelques exemples en C, Rust et Pseudocode accompagneront mon propos. Le code complet est disponible en annexe. Je vous recommande toutefois de ne pas trop vous y attarder et de considérer qu’il n’y a pas de réponse parfaite et encore moins d’implémentation unique à une solution. Aussi, j’espère que vous me pardonnerez les simplifications que je fais en Rust étant un langage plutôt verbeux, j’ai dû tailler quelques morceaux pour en extraire l’essentiel.
J’en profite pour vous prévenir que je suis conscient de maîtriser certains
aspects et pas d’autres. Même si j’ai le sentiment d’être dans le vrai,
n’hésitez pas à me corriger si vous rencontrez des erreurs. Il y en aura
forcement, même après une centaine de relectures. Je serai heureux de recevoir
les remarques ainsi que les opinions par mail
(zinger.ad@gmail.com) on dans un commentaire sur mon github.
Chapitre 1 - Les machines à états
Ce que tu peux faire de mieux pour ton programme, c’est d’en faire une machine à états.
Dans un projet, on souhaite une machine à états quand une partie du programme gère un contexte global ou temporaire, subit des modifications lors d’appels exterieurs ou doit réagir à différentes entrées et retourner un résultat cohérent avec celles-ci, en tenant compte d’un historique. Une telle machine peut être utilisée pour modeler un composant d’un système distribué par exemple, et même le système complet. Chaque état, dans ce cas, peut contenir un snapshot à un instant T qui inclue l’état de la mémoire des composants (processeurs) ainsi que les messages en transit. Plus généralement, on souhaite une machine à états lorsqu’une fonction donne une sortie différente après chaque appel. On remarque que les itérateurs et les générateurs sont aussi des genres de machine à états.
Il y a différentes façons d’aborder le problème. La façon scolaire, linéaire que la plupart des raisonnements humains vont produire. Cette façon de faire pourra, entre autres, ressembler à un analyseur LL ou LR car les implémentations peuvent être très similaires. Souvent, ces deux méthodes ne se différencient que dans les structures qu’elles utilisent dans l’implémentation. On y trouvera, dans tous les cas la logique suivante : “si j’ai tel événement dans tel contexte, je passe à tel état suivant”. Au début de mes études, je codais de nombreuses fonctions qui s’appelaient les unes les autres, pleines de conditions et de branchements.
Un raisonnement de la sorte, avec une implémentation bien linéaire, des états qui s’empilent puis se réduisent, est efficace si on souhaite développer rapidement un petit morceau de code. Mais cela devient vite ingérable dans une application qui traversera beaucoup d’états, si en plus aucun des branchements ne peut être auto-généré ou encore que les transitions se complexifient. Idem, si le projet change ses grammaires ou s’il s’avère qu’on commence à y trouver des conflits.
Depuis longtemps, on élude ces problèmes en utilisant des générateurs de parseurs. Vous avez peut-être déjà entendu parler de YACC et LEX. Ce genre de générateur existe dans de nombreux langages et sous de nombreuses formes. Il me semble qu’aujourd’hui, leur utilisation est moins répandue ou moins célèbre. Dans mon entourage, parmi mes amis et collègues, je trouve peu de gens à qui cela laisse de bons souvenirs. Pourtant, selon moi, c’est la meilleure solution pour générer des machines à états encore aujourd’hui. Se plonger dans une grammaire sous le format BNF, aussi ennuyeux que cela puisse être, vous fera gagner une base de code propre et un temps considérable. Toute méthode a ses avantages et ses inconvénients. Bien sûr, dans certains cas, il sera plus simple d’écrire rapidement un analyseur à la main ou en utilisant une bibliothèque tierce.
Depuis quelques temps, on développe aussi des analyseurs par petits morceaux. Ces combinaisons de parseurs ont des bons côtés. Déjà, on ne dépend pas d’un générateur et, dans le meilleur des cas, on ne dépend pas non plus d’une bibliothèque. Le développement est linéaire et correspond plus au attente d’un développeur classique : je lis, je change d’état. Les états sont des parseurs, des fonctions. Bien sûr, on risque de retomber dans le piège des nombreuses fonctions pleines de conditions, il faut faire attention.
Ensuite, il y a la manière React ou Redux. Car en faisant du React, on fait des parseurs, ou plutôt, des machines à états. L’un ou l’autre, c’est presque pareil.
// green thread 1
function state_machine() {
// création de la machine à états
let (state, dispatch) = use_state(reducer_function, state_1);
foo(dispatch).then(() => {});
}
// green thread 2
async function foo(dispatch) {
let state2 = await recv_async_call();
dispatch(state2); // changement d'état
}
React permet de recharger des composants (des machines à états) avec des
nouveaux états. On a à disposition des fonctions comme useReducer et
useState, qui sont les plus utilisées. Ces méthodes permettent chacune de
créer une fonction de mise à jour (dispatch) en donnant pour paramètres une
valeur initiale et une routine de réduction : (current_state, action) =>
new_state. Une fonction de réduction permet de créer un nouvel état à partir
de l’état courant et d’un événement, telle qu’une entrée utilisateur. Pouvoir
donner cette fonction en argument permet de centraliser les comportements
complexes en fonction d’un contexte. Avec useState, on se limite à prendre
pour argument un état initial, il utilise sa propre fonction de réduction où le
paramètre action sera le nouvel état.
L’idée n’est pas tout a fait de reproduire React dans son integralité, ni
d’entrer dans des concepts d’effets algébriques, mais bien de reprendre
certaines bases qui pourraient donner des résultats visuellement identiques.
Par exemple, le fait que useState soit composé d’un useReducer est bien
exacte. Voici un extrait de l’implémentation actuelle qui, si l’action est
une fonction, retourne le résultat de celle-ci, sinon retourne l’objet de
l’action. Cette routine est le réducteur utilisé à l’appel de useState.
function basicStateReducer<S>(state: S, action: BasicStateAction<S>): S {
return typeof action === 'function' ? action(state) : action;
}
Le fonctionnement d’une machine à états similaire React est alors décrit par des structures génériques dans une file et une fonction de transition si nécessaire. Grâce à cette méthode, nous pouvons utiliser la généricité afin de simplifier l’implémentation finale.
function onStateChange_Tests(state) {
if (state.view == "view1") return showView1();
else if (state.view == "view2") return showView2();
else return showView3();
}
function onStateChange_Generique(state) {
return state.showView();
}
Chapitre 2 - Utiliser une machine à état
Une machine à états est flexible, on l’adapte en fonction du besoin. Un itérateur, un générateur ou encore un analyseur sont des types de machines à états. Parfois, un simple appel à un timeout peut en cacher une : “en cours -> annulé”, “ouvert -> fermé”. Mais parmi tous, l’analyseur est un cas particulier. Un parseur suppose une fin à ses états. Que le programme soit écrit à l’aide d’un générateur ou avec la méthode des combinaisons, on attend des états qu’ils se résolvent et, pour finir, qu’ils arrivent à l’état ultime : la sortie du programme avec succès.
Pourtant, avec la méthode React, on peut écrire des itérateurs, des parseurs et toute sorte de machines à états finies et infinies. C’est pour cette raison qu’elle est extrêmement efficace pour la gestion d’une application. Faire avancer ses états avec React se résume à empiler des événements et les traiter un par un afin d’appliquer les modifications adéquates.
Les morceaux de codes qui suivront font partie d’une expérience : créer une bibliothèque de zéro, avec les mêmes attentes qu’on pourrait avoir de React. Le sujet de l’expérience ici sera un programme simpliste où j’implémente un echo volontairement complexe (à ne pas refaire chez soi).
Voici le comportement attendu :
- la sortie standard affichera
waiting for an entry. you wrote: ${entrée}suivit deCan you write something else?.you wrote: ${entrée}puisCan you write something else? (${compteur}). Puis répéter à partir de 3.
Le programme devra s’arrêter à la lecture du mot clef “exit”. Et avancera à chaque lecture d’une entrée utilisateur.
Je commence par créer une structure State représentant un état contenant une
méthode appliquant une des étapes du programme et certaines variables
contextuelles. La méthode associée dynamiquement variera lors d’une transition
ou bien pourra être modifiée, puis validée avec une fonction dispatch que
proposera cette logique. Chacune des méthodes sera représentative de l’état du
programme (1, 2 ou 3 et plus). Visuellement, il suffira de lire une fonction
pour comprendre ce qu’un état va avoir comme effet de bord. Pour le
développement du projet, un diagramme d’états suffira pour comprendre la
logique de l’application, ce qui est très agréable.
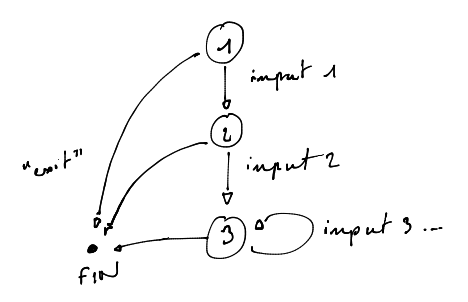
La figure ci-dessous montre l’implémentation de chacune des étapes de l’automate. Les lignes A2 et B3 montrent comment changer d’état après une exécution. La ligne C3 modifie un contexte en incrémentant un compteur pour l’itération suivante. Les autres lignes sont des effets de bord.
void step_1(struct State *self)
{
printf("waiting for an entry\n"); // A1
self->step = step_2; // A2
}
void step_2(struct State *self)
{
printf("you wrote: %s\n"); // B1
printf("Can you write something else?\n", self->val); // B2
self->step = step_n; // B3
}
void step_3_and_more(struct State *self)
{
printf("you wrote: %s\n"); // C1
printf("Can you write something else? (%i)\n", // C2
self->val, ++(self->count)); // C3
}
Il est important de noter qu’ici plusieurs lignes modifient la valeur de l’état. Ces valeurs sont modifiées en prévision de l’itération suivante de mon programme. Autrement dit, je ne modifie pas mon état actuel, mais je construis l’état suivant. Dans certains cas, cette façon de faire peut poser problème, notamment si le programme utilise plusieurs threads qui ont accès à cette variable parallèlement. Parmi les problèmes qu’on peut rencontrer, dans le multithreading, le fait de rendre l’état courant immutable ou limiter sa mutabilité devient une nécessité. Ne touchez pas à l’état courant, construisez-en un nouveau ou entourez-le de mutexes. J’évoque le terme d’itération dans ce paragraphe. En quelques mots, le coeur de mon programme est une boucle infinie, qui à chaque nouvelle mise à jour exécutera la même fonction. La logique ne change pas, l’état si.
int state_machine()
{
struct Reaction *re = use_state(make_init_state);
struct State *st = re->state;
if (st->before(st) == 1)
{
pthread_join(st->scan, NULL);
return EXIT_SM;
}
st->step(st);
async_scan(re);
return CONTINUE_SM;
}
Voici comment une machine à états infinie pourrait s’implémenter. La complexité
(absurde) de l’exemple par rapport à l’objectif montre comment on peut se
défaire d’une série de conditions et d’intrications de fonctions. Par exemple,
l’optimisation de la routine before qui en premier lieu retourne forcément 0,
n’ayant aucune entrée à lire, ne fera d’abord rien, puis se mettra à jour pour faire
quelque chose. Dans un projet plus réaliste, ces petites différences sont
importantes. Elle permet de contrôler à chaque état les effets de bord
nécessaires ou superflus, variants et invariants.
Chapitre 3 - La file d’états
Abordons une partie importante de l’exemple : la lecture de
l’entrée utilisateur. C’est-à-dire l’endroit où j’appelle la méthode dispatch
associée à la machine à états. Cette méthode ajoute dans une file un nouvel
objet associé à une fonction de réduction, selon qu’on ai utilisé use_state
ou use_reducer.
void *scan(void *_re)
{
// Récupération de la machine à états à altérer
struct Reaction *re = (struct Reaction *)_re;
struct State *new_state = malloc(sizeof(struct State));
memcpy(new_state, re->state, sizeof(struct State));
int _ = scanf("%299s", new_state->val);
dispatch(re, new_state);
}
Ce modèle de machine à états enfile des objets pour les traiter de façon synchrone, mais rien n’empêche que l’accumulation des événements soit asynchrone ou parallèle. Il est donc important de se poser quelques questions sur la résistance du modèle face au parallélisme.
Dans ce programme simple, j’ai de la chance pour deux raisons. La première est
que scanf en C a une implémentation telle que, même si plusieurs threads
écoutent en même temps, seulement l’un d’entre eux se réveillera avec un
buffer. Mais imaginons que le programme écoute plusieurs entrées différentes,
comme des appels réseau ou des notifications de l’OS. Les opérations d’enfilage
et de défilage peuvent être concurrentes et poser des problèmes de
synchronisation.
Pour résoudre les problèmes liés au parallélisme dans un modèle de machine à états, on peut utiliser des techniques de partage de données appelées X producteur(s) Y consommateur(s) où X et Y peuvent prendre la forme de “unique” ou “multiple”. Il existe de nombreuses implémentations et approches différentes, au moins une par bibliothèque standard. Celle qui est implémentée dans la bibliothèque Reagir, la mienne, n’est peut-être pas la plus efficace, mais elle est facile à comprendre pour commencer.
static void send_state(struct Entry e)
{
struct Reagir *re = e.rea->re; // S1
pthread_mutex_lock(&re->mutex); // S2
while (re->queue_len == QUEUE_MAX_LEN) // S3
pthread_cond_wait(&re->pop_condvar, &re->mutex); // S4
re->queue[re->push_ptr] = e; // S5
re->push_ptr = (re->push_ptr + 1) % QUEUE_MAX_LEN; // S6
re->queue_len++; // S7
pthread_cond_signal(&re->push_condvar); // S8
pthread_mutex_unlock(&re->mutex); // S9
}
static struct Entry receive_state(struct Reagir *re)
{
pthread_mutex_lock(&re->mutex); // R1
while (re->queue_len == 0) // R2
pthread_cond_wait(&re->push_condvar, &re->mutex);// R3
struct Entry e = re->queue[re->pop_ptr]; // R4
re->pop_ptr = (re->pop_ptr + 1) % QUEUE_MAX_LEN; // R5
re->queue_len--; // R6
pthread_cond_signal(&re->pop_condvar); // R7
pthread_mutex_unlock(&re->mutex); // R8
return e;
}
void dispatch(struct Reaction *rea, void *arg)
{
struct Entry e = {(struct PrivReaction *)rea, arg};
send_state(e);
}
Lorsqu’on appelle la fonction dispatch, on créé une nouvelle entrée qui sera
traitée par la bibliothèque pour passer d’un état à un autre. La fonction
dispatch prend en argument la structure Reaction qui représente la machine
à états que l’on souhaite altérer, ainsi qu’un second argument qui peut être un
nouvel état (si on utilise use_state) ou une action (si on utilise
use_reducer). Cela permet de continuer à avancer pas à pas en enfilant des
fonctions de réduction qui seront appelées séquentiellement avec leurs
arguments. En d’autres termes, cela consiste à enfiler des fonctions de
réduction et l’argument d’événement action.
Prenons un peu le temps de lire l’algorithme de la figure précédente. On remarque que ce code contient plusieurs verrous. Un verrou coûte du temps au processeur. Il est préférable, si possible, d’éviter d’en invoquer un. Bon, cette implémentation est peut être suffisante pour mon exemple.
Le deuxième point qui me rend chanceux dans cette implémentation, c’est que l’utilisation que je fais de ma machine à états est synchrone. Même si j’utilise deux threads différents. Je ne lis pas d’entrée utilisateur pendant l’exécution de la boucle de la machine à états, ou même avant. À aucun moment, je peux envoyer un événement ET en recevoir simultanément. Les lignes S2, S9 R1 et R8 sont donc inutiles dans ce cas. Malgré tout, les lignes S3, S4, S8 et R2, R3 et R7 sont encore nécessaires pour ne pas faire boucler le CPU sans raisons. Si vous n’êtes pas familier avec ce mécanisme, je vous propose de vous documenter sur les variables conditionnelles et leurs usages avant de continuer.
Même si mon programme communiquait avec d’autres, si je m’assure d’un ping pong
où chaque instance attend la réponse de l’autre, je peux écrire ces instances
sans aucun appel de lock unlock. Autrement dit, tant qu’on peut considérer
que l’ensemble du système fonctionne sur un unique thread en additionnant les
exécutions concurrentes, on peut se passer de verrou. Le fait d’avoir une
utilisation synchrone de cette file est l’unique justification valable pour
retirer les mutexes. Des appels parallèles auraient des résultats
imprévisibles. Par mesure de sécurité, il faut toujours entourer les variables
conditionnelles par des verrous. Tenez ça pour une règle d’or.
Dans ce cas, je retire quelques utilisations de mutexes et ça marche. Mais nous nous bornerons à des systèmes mono-threadé. L’implémentation naïve ne suffit pas dans les cas suivants. Si on souhaite quelque chose de plus puissant qui nous autorise des lectures et écritures parallèles, il faut se tourner vers des structures plus efficaces. Dans un contexte où on recevrait des évenements trop rapidement, une structure de données non-bloquante pourrait être intéressante. Il y a un grand nombre d’implémentation possible, encore, à commencer par celle qui utilise deux mutexes différents pour la tête de file et son bout. Les producteurs se partageraient un verrou et le consommateur sera plus rapide à lire, ayant le monopole sur le défilement.
Plus rapide encore, une version de la file de Michael & Scott propose une solution n’utilisant aucun mutex. L’algorithme tire avantage des capacités atomiques du processeur. En d’autres termes, la lecture ou l’écriture d’une variable sera organisé parmi les différents threads dans un ordre spécifié.
Chapitre 4 - Rappel atomique
Une opération atomique, c’est lire, écrire, effectuer une opération basique
comme un ET ou un OU, sur une petite partie de la mémoire comme par exemple
là où se trouve un entier. Cette opération garantie qu’aucun autre thread ne va
tenter de lire ou écrire pendant le temps de l’opération. Enfin, ces
opérations garantissent que le processeur respectera un certain ordre défini
par les instructions, éloignant les comportements indéfinis. Ainsi,
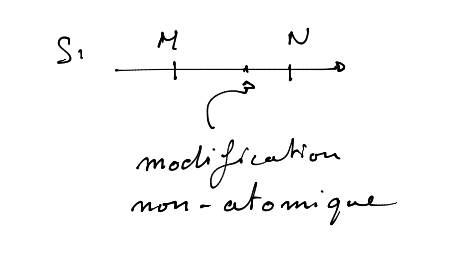
un programme comme décrit ci-dessous aura une fin déterministe alors qu’un
programme similaire avec une incrémentation non-atomique serai
non-deterministe.
add(i: AtomicInt*):
fetch_add(i, 1);
main():
let i = AtomicInt::new(0);
let th1 = Thread::spawn({ add(&i) });
let th2 = Thread::spawn({ add(&i) });
join(th1, th2);
assert!(i == 2);
On associera toujours une opération atomique à ce qu’on appelle un
ordonnancement. Avant de poursuivre ce chapitre, il est important d’en préciser
quelques caractéristiques. Par exemple, une opération de lecture, également
appelée chargement, peut être soumise à un ordonnancement nommé ACQUIRE.
Cette opération respectera certaines contraintes, lesquelles sont :
- Il est impossible pour le processeur de réordonner les lectures ou écritures après le chargement de la variable.
- Les écritures effectuées dans d’autres threads sont visibles pour le thread lecteur.
La première règle est garantie par des instructions de barrières mémoire qui permettent de maintenir un ordre cohérent entre le programme écrit et son interprétation par le processeur. Le deuxième point est plus complexe, car il permet au thread courant d’établir un ordre chronologique et les relations “arrive avant” entre les accès à une variable. Le thread qui charge une variable dans une zone mémoire “A” interprètera chronologiquement chaque écriture dans des threads parallèles afin de trouver la dernière valeur dans A. Cependant, les relations arrivé avant sont des interprétations qui ne concernent que le thread courant. Du fait, d’autres threads peuvent avoir une vision chronologique différente des événements. Les autres ordonnancements mentionnés plus tard ont des comportements plus ou moins similaires.
De base, sur un processeur Intel, tout mouvement, selon ce que l’on comprend,
est atomique. Prenons l’instruction mov sur x86. Cette instruction est
courante dans un programme, elle peut être produite par une assignation de
variable ou encore un passage d’argument. Cette instruction permet selon son
utilisation de copier une valeur ou de copier l’adresse de cette valeur. C’est
la différence entre un déplacement par copie ou par référence. Elle peut
être utilisée pour lire ou écrire, selon le sens dans lequel on place les
arguments. Lorsqu’une instruction de lecture est exécutée, elle a un
comportement similaire à l’ordonnancement défini par ACQUIRE et lorsqu’une
instruction d’écriture est exécutée, elle a un comportement similaire à
l’ordonnancement défini par RELEASE. Ce, sans avoir besoin de préciser quoi
que ce soit. En fait sur x86, l’ordonnancement RELAXED est chimérique.
C’est-à-dire que les compilations d’opérations atomiques avec le flag RELAXED
produiront le même résultat que des opérations dites non-atomique ou des
opérations atomiques ACQUIRE/RELEASE.
Toutes les opérations de lecture et d’écriture, dans un certain sens, sont donc
“atomiques” sur x86. Mais ce n’est pas le cas pour tous les processeurs. Sur
certains macs, ou quelques consôles de jeu, qui ont un processeur ARM, on
devra utiliser des instructions telle que dmb (data memory barrier) pour
préciser un ordre ACQUIRE/RELEASE. L’instruction dmb garantit que toutes
les instructions de lecture ou écriture en mémoire exécutées avant elle soient
bien terminées avant que de passer à d’autre instructions. Il convient alors de
dire, en écrivant du code plus haut niveau, comme du Rust ou du C, que
toutes les opérations sont non-atomique tant que le développeur ne le précise pas.
En ce qui concerne les variables volatile, il n’y a pas de différence particulière. Cependant, le compilateur tachera de toujours utiliser l’adresse réelle de la variable sans optimiser grâce à des variables temporaires ou en les remplaçant par une logique plus appropriée, après du tree shaking par exemple. Le compilateur est donc simplement informé du fait que la variable est sucéptible de changer dans d’autres exécutions parallèles. Il est important préciser que les instructions produites resteront souvent les mêmes qu’avec des variables globales basiques, et que la compilation ne génèrera aucune barrière mémoire comme elle pourrait le faire avec des variables atomiques. Cela dit, l’utilisation de ce genre de mot-clef se perd avec le temps et les impactes peuvent varier d’un langage à un autre.
Le processeur, pour plusieurs raisons, peut avoir le droit de superposer des
opérations sur un même thread. C’est ce qu’on appelle l’out-of-order (OOO).
Ce qui peut rendre un programme avec des exécutions parallèles difficiles à se
représenter et donc complexes à développer. Avec des opérations atomiques ainsi
que les flags Acquire, Release, AcqRel et SeqCst, on peut forcer le
processeur à ne plus superposer certaines lectures et écritures. On peut aussi
forcer un certain ordre, ou du moins certaines contraintes.
while (ip < iend-15) {
U32 c = cached; cached = MEM_read32(ip); ip += 4;
Counting1[(BYTE) c ]++;
Counting2[(BYTE)(c>>8) ]++;
Counting3[(BYTE)(c>>16)]++;
Counting4[ c>>24 ]++;
c = cached; cached = MEM_read32(ip); ip += 4;
Counting1[(BYTE) c ]++;
Counting2[(BYTE)(c>>8) ]++;
Counting3[(BYTE)(c>>16)]++;
Counting4[ c>>24 ]++;
c = cached; cached = MEM_read32(ip); ip += 4;
Counting1[(BYTE) c ]++;
Counting2[(BYTE)(c>>8) ]++;
Counting3[(BYTE)(c>>16)]++;
Counting4[ c>>24 ]++;
c = cached; cached = MEM_read32(ip); ip += 4;
Counting1[(BYTE) c ]++;
Counting2[(BYTE)(c>>8) ]++;
Counting3[(BYTE)(c>>16)]++;
Counting4[ c>>24 ]++;
}
La figure ci-dessus est extraite de l’implémentation de la construction d’un histogramme dans la bibliothèque zstd. Il peut sembler étrange de couper un compteur en 4 parties et d’en faire la somme plus tard. Surtout sur un seul thread, s’il y avait eu une strategie multithreadé on aurait pensé à un diviser pour mieux rêgner, ou dans ce cas précis pour rêgner plus vite. En réalité, c’est exactement le but recherché. Un processeur OOO peut potentiellement exécuter simultanément les opérations suivantes : la lecture de la mémoire à l’adresse ip, les affectations des variables c en cache, et les accès aux différents tableaux.
Parmi les différents ordonnancements possibles, celui qui contraint le plus la
sémantique d’un programme est SeqCst (Séquentiellement Consistant). Chaque
paire d’opérations atomiques SeqCst a le même comportement qu’une paire
ACQUIRE-RELEASE, en plus d’une caractéristique fondamentale : une série
chronologique S des événements de lectures et d’écritures est visible par
tous les threads du programme. Dans la conception d’un algorithme performant,
la construction de S par le processeur peut être un overhead à prendre en
compte. toutefois, il peut être indispensable pour résoudre plusieurs
problématiques, notamment si notre programme est constitué de plusieurs threads
de lecture et d’écriture.
let x = false
let y = false
let z = 0
write_x():
x.store(true)
write_y():
y.store(true)
read_x_then_y():
while !x.load() {};
if y.load():
z.fetch_add(1)
read_y_then_x():
while !y.load() {};
if x.load():
z.fetch_add(1)
main():
let th1 = spawn(write_x)
let th2 = spawn(write_y)
let th3 = spawn(read_x_then_y)
let th4 = spawn(read_y_then_x)
join(th1, th2, th3, th4)
assert(z != 0) // Peut rater
Le pseudocode ci-dessus est un extrait de la documentation des ordonnancements
mémoires en c++. Il est probable qu’en tant que lecteur, vous n’ayez pas prêté
suffisamment d’attention à la phrase “D’autres threads peuvent avoir une
vision chronologique différente des événements”, lors de la présentation de
ACQUIRE. Ce manque d’attention est naturel et devrait être pris en compte par
celui ou celle qui formule une explication, en répétant par exemple. Donc,
arrêtons-nous sur cet algorithme.
Si j’utilisais par défaut l’ordre défini par ACQUIRE-RELEASE, les threads
th3 et th4 auraient potentiellement une vision différente de l’historique
des accès aux variables x et y, car elles ont étés modifiées par deux
threads différents. Utiliser une contrainte plus élevée SeqCst qui partage la
chronologie S des accès à la mémoire à travers le processeur permet donc de
résoudre les data races entre ces threads. Autrement dit, si pour th3
l’écriture de x est séquentiellement avant l’écriture de y alors pour
th4 aussi.
Notez également que la garantie d’une contrainte d’ordonnancement quelle
qu’elle soit est toujours rompue lorsqu’un accès à la zone mémoire est
non-atomique ou possède des contraintes moins élevées. On en déduit donc qu’une
lecture SeqCst N aura pour résultat soit la dernière valeur écrite par une
modification SeqCst M dans S, soit toute autre valeur écrite par une
modification non-atomique, RELEASE ou RELAXED effectuée entre M et N qui
n’est pas dans S.
Une variable peut être atomique dans le cas où elle est assez petite. Elle est
généralement d’un type primitif, un pointeur, sur 32 ou 64 bits. On peut lui
donner des ordonnancements d’accès en lecture et écriture de manière à ce que
différents threads ne tombent pas dans des data races. Et dans tout les cas,
il est préférable, si on utilise ces variables, de donner l’ordonnancement
SeqCst qui est la contrainte la plus élevée avant de tenter autre chose. En
ce qui concerne les conteneurs (set, hashmap, etc) une opération atomique est
bien plus complexe à réaliser et nécessite parfois des algorithmes de consensus
avancés.
Chapitre 5 - Atomique
Il existe certains cas où tout se déroule au mieux, même sans préciser
l’atomicité dans le code, ou avec des ordonnancements plus faibles que
SeqCst. Notamment sur des processeurs x86. Cela devient intéressant de
savoir pourquoi et comment le mécanisme se traduit en instructions.
Pour observer les instructions qu’un processeur Intel peut comprendre, on peut commencer par écrire avec un langage haut niveau les différents concepts atomiques que la plupart des langages nous permettent d’utiliser. Je vais donc écrire un programme de différentes façons, avec des méthodes plus ou moins validées par la communauté des développeurs. Ce programme consiste principalement en deux threads. L’un produit, l’autre consomme. Le producteur incrémente une variable jusqu’à ce qu’elle soit égale à 5, l’autre lit tant que la même variable ne vaut pas 5. Après quoi, le programme s’arrête.
Je vous épargnerai les déclarations de bibliothèques et la fonction de démarrage. Préférant me concentrer sur les routines des différents threads.
La première version utilise des mutexes.
void *producer_thread(void *counter)
{
int c = 0;
while (c != 5)
{
pthread_mutex_lock(&COUNTER_MUTEX);
*(int *)counter = ++c;
pthread_mutex_unlock(&COUNTER_MUTEX);
}
}
void *consumer_thread(void *counter)
{
int c = 0;
while (c != 5)
{
pthread_mutex_lock(&COUNTER_MUTEX);
c = *(int *)counter;
pthread_mutex_unlock(&COUNTER_MUTEX);
}
}
Dans cette version, mon postulat est que l’invocation d’un verrou autour de ma
variable est inutilement coûteuse. En plus, je dois gérer une variable globale
pour en contrôler l’accès. Cette méthode est particulièrement utilisée lorsque le
type de counter n’est pas primitif. Si c’était une structure ou un tableau,
cette méthode serait acceptable.
À noter qu’ici, il serait simple de modifier le programme de façon à ce qu’on puisse avoir plusieurs producteurs sans créer de comportement indéfini. Il suffirait d’ajouter dans la boucle du producteur un test de la variable pour voir si elle est déjà égale à 5. Le cas échéant, on retourne une erreur ou l’on sort simplement de la fonction.
Voilà la deuxième version:
void *producer_thread(void *counter)
{
int c = atomic_fetch_add_explicit(
(atomic_int *)counter, 1,
__ATOMIC_RELEASE);
while (c != 4)
c = atomic_fetch_add_explicit(
(atomic_int *)counter, 1,
__ATOMIC_RELEASE);
}
void *consumer_thread(void *counter)
{
int c = atomic_load_explicit(
(atomic_int *)counter,
__ATOMIC_ACQUIRE);
while (c != 5)
c = atomic_load_explicit(
(atomic_int *)counter,
__ATOMIC_ACQUIRE);
}
Cette fois-ci, plus de mutex ni de verrouillage. On utilise une opération
atomique basique fetch_add qui va, sans surprise, incrémenter la valeur du
compteur. fetch_add produit sur ma machine la ligne instruction lock
xaddl %edx, (%rax)`. C’est une opération d’addition entre edx et
rax, avec le préfixe lock. Ce préfixe permet entre autres de préciser au
processeur que la valeur de la cible ne peut ni être changée ni lue pendant
l’incrémentation. Utiliser cette fonction est considéré comme wait-free si
vous êtes familier avec les types d’algorithmes multithreadés.
La version ci-dessus nous empêche d’avoir plusieurs producteurs. Effectivement,
on risque d’avoir une variable temporaire c qui ne soit plus la bonne,
cependant, on continue à incrémenter le compteur. C’est ce qu’on appel un data
race. Ce risque de data race est à prendre en compte. Même si dans ce cas,
tout va bien, ajouter un ou plusieurs producteurs en parallèle pourrait créer
des boucles infinies.
La dernière version ci-dessous n’utilise même plus d’opérations atomiques et
fonctionne parfaitement. Cette version ne marche que parce que les instructions
mov ont le même comportement entre eux que des variables atomiques avec
les ordonnancements ACQUIRE-RELEASE sur un processeur Intel. De plus, le contexte
n’a que deux threads.
void *producer_thread(void *counter)
{
int c = 0;
while (c != 5)
*(int *)counter = ++c;
}
void *consumer_thread(void *counter)
{
int c = 0;
while (c != 5)
c = *(int *)counter;
}
En pratique, que l’on utilise RELAXED ou ACQUIRE-RELEASE ne change rien.
Cela dit, utiliser l’ordonnancement par défaut, SeqCst, reste la meilleure
des pratiques. Ne vous risquez pas trop à changer cette règle pour des bouts de
chandelle de performance.
Cette version ne permet pas du tout d’avoir de multiples producteurs. On
pourrait la modifier légèrement en utilisant la fonction atomique
compare_and_swap dans la boucle du producteur. Cette fonction permet de
vérifier si la valeur de c est bien celle qui se trouve dans le compteur au
moment de l’échange. Et si ce n’est pas le cas, on récupère sa valeur actuelle,
et on essaie à nouveau si besoin. compare_and_swap est l’élément qui manquait
aussi à la deuxième version. Cependant, si l’utilisation de fetch_add est
wait-free, l’équivalent sans les data race avec compare_and_swap est
lock-free. La figure ci-dessous pourra vous donner un aperçu concis des
niveaux qu’un algorithme multithreadé peut avoir.
atomic_int i;
// obstruction-free
lock(MUTEX);
i++;
unlock(MUTEX);
// lock-free
int c = load(&i);
while (!cas(&i, c, c + 1))
c = load(&i));
// wait-free
atomic_fetch_add(&i, 1);
Cette figure présente plusieurs classes d’algorithmes. Précisons que ces exemples n’ont de sens que dans des systèmes concurrents, où ils peuvent interférer simultanément avec d’autres composants ayant des effets sur des éléments communs. Les noms ou les caractéristiques associées à ces classes sont organisés selon l’ordre suivant: un algorithme wait-free est également lock-free, et un algorithme lock-free est également obstruction-free. Avant de détailler ces termes afin d’en comprendre leur signification, il est utile de souligner un point important. En effet, le fait de nommer une routine wait-free, lock-free ou obstruction-free indique le comportement garanti par celle-ci. Cependant, chaque catégorie présente des faiblesses absentes dans les catégories supérieures. Par exemple, un algorithme obstruction-free peut avoir des inconvénients alors qu’un algorithme wait-free n’en aura pas. En outre, on entend ici qu’un tel algorithme pourra interferer avec au moins un homologue de lui-même sur des threads parallèles.
À présent que le contexte d’utilisation de ces termes est claire, nous pouvons les définir sans ambiguïtés. Commençons par la classe d’algorithme obstruction-free, cette classe, donc, décrit une routine qui garantit que : si elle est seule à s’éxecuter sur son système durant son intervalle d’action, alors elle pourra faire avancer son état sans être interrompue. Cependant, si d’autres routines s’exécutent en parallèle, une routine de cette classe peut être bloquée soit par l’utilisation d’un verrou, soit par une stratégie de veille particulière. La durée de ce blocage, bien qu’habituellement brève, est indéterminée. Finalement, le plus grand défaut de ce type de routine est son incapacité à faire avancer son propre état lors d’une interférence.
La classe supérieure lock-free est moins contraignante. Elle est bien plus préférable dans la majeure partie des cas, bien qu’elle ne se prête pas à tous les scénarios. Elle garantit pour une routine que : si elle s’éxecute en parallèle d’une copie d’elle-même ou d’autres parties de l’algorithme, alors parmi les différentes exécutions en cours sur le système (elle comprise) une pourra terminer lors d’un certain nombre de ses étapes. Elle tentera toujours de faire avancer son propre état, quitte à recommencer du début. Contrairement à un algorithme obstruction-free, elle est potentiellement capable d’agir sur elle-même. C’est-à-dire qu’elle peut, dans une situation d’attente, s’arrêter, s’annuler, continuer ou recommencer, sans intervention extérieure.
Les algorithmes de la classe “wait-free” ne se préoccupent pas des autres threads. Les conflits d’accès simultanés sont gérés à un niveau plus bas par le processeur. Par exemple, grâce à une instruction atomique “read-and-write” qui protège une variable pendant la lecture, la mise à jour et l’écriture telle que
fetch_add. De même, les instructionsswapoustoremodifient une variable sans se soucier de conditions particulières. Contrairement à une classe d’algorithmes “lock-free”, qui doit attendre pour réaliser des effets de vérifier si des accès concurents ont eu lieu, et le cas échéant recommencer, une routine “wait-free” se termine sans tenir compte des autres threads concurrents. En d’autres termes, si elle est exécutée en parallèle avec une copie d’elle-même ou d’autres parties de l’algorithme qui partage la même structure de données, elle se terminera avec succès.
Revenons aux ordonnancements. Spécifier un ordre dans lequel les threads vont
accéder à une variable et les contraintes sur un seul thread est possible dans
quasiment tout les langages permettant la parallélisation des exécutions. En
Go, il n’est possible d’utiliser que l’ordonnancement SeqCst. En Rust, les
types atomiques sont identiques au C/C++, bien qu’entre ces langages, certains
choisissent de déprecier des méthodes et d’autre non. L’idée cependant est là.
Avec l’atomicité, on peut par exemple simuler ce que ferait un mutex protegeant
une variable. Voici l’exemple le plus classique que vous pourrez trouver à
propos des opérations de lectures et écritures atomiques.
fn thread_a(atomic_bool: Arc<AtomicBool>, val: Arc<AtomicU32>) {
val.store(42, Ordering::Relaxed);
atomic_bool.store(true, Ordering::Release);
}
fn thread_b(atomic_bool: Arc<AtomicBool>, val: Arc<AtomicU32>) {
let mut b = atomic_bool.load(Ordering::Acquire);
while !b {
b = atomic_bool.load(Ordering::Acquire);
}
let v = val.load(Ordering::Relaxed);
assert!(b);
assert_eq!(v, 42);
}
La figure ci-dessus est un exemple de synchronisation. De la même manière qu’un
garde (mutex verrouillé) relaché dans un thread A puis acquis dans un thread B,
ce qui a été stocké par le thread A est visible par le thread B. Dans la mesure
où la modification de atomic_bool est garantie d’être faite après celle de
val dans A, et à l’inverse, la lecture de atomic_bool est garantie d’être
faite avant celle de val dans B.
Une écriture avec un ordre atomique RELEASE implique qu’aucune écriture ou
lecture dans le même thread ne peut être réorganiser par le processeur après le
stoquage, que l’opération soit atomique ou non-atomique. Autrement dit, ce qui
est écrit ou lu avant sera vraiment écrit ou lu avant. De plus, toute écriture
dans une variable devient visible par tous les autres threads voulant lire avec
un ordre atomique ACQUIRE. Pour résumer simplement, val est comme protégée
par un mutex. Cette façon d’attendre activement l’accès à une ressource
s’appelle un spinlock. Très utile dans certains cas, et bien trop gourmand en
temps de CPU dans d’autres.
Sans l’utilisation de lecture et écriture atomique, un programme multithreadé
de la sorte se risquerait à un comportement indéfini pour quelques processeurs.
Et d’ailleurs le compilateur de Rust ne permettrait pas d’écrire le spinlock
dans la figure précédente sans l’utilisation du mot-clef unsafe.
Chapitre 6 - L’état dans lequel je suis
Une machine à états conserve toujours au moins son état actuel. Que cet état soit représenté par une variable, une pile, ou simplement par la position de son l’exécution sur la stack.
Pour Reagir (ma bibliothèque) comme pour React, les états sont des variables qu’on récupère à un moment de l’exécution. Dans l’implémentation de Reagir, l’état ne peut pas se trouver sur la pile. Si c’était le cas, on ne pourrait jamais dépiler les exécutions et le programme grossirait en mémoire continuellement. Les états de la bibliothèque Reagir sont donc quelque part sur le tas, ou globaux. Par défaut, on les considère constants ou statiques.
À l’écriture d’un programme, ce n’est pas toujours pratique d’avoir des états constants et immutables. Dans la plupart des exemples trouvé avec React, l’état est modifié au fur et à mesure. Personnellement, j’aime aussi considérer l’état comme une base avec laquelle je profile l’exécution, puis j’en tire l’état suivant si besoin. Contrairement au Rust, C me donne la liberté de créer des variables statiques mutables sans protections, ce qui rend d’ailleurs ce vieux langage non memory safe. En contre partie, ça me permet de ne pas à avoir à allouer de mémoire dynamiquement, et surtout, d’avoir un code simple.
void *make_init_state()
{
static char val[300] = {'\0'};
static struct State st = {
val,
0,
zero,
first_print,
0,
};
return &st;
}
int state_machine()
{
struct Reaction *re = use_state(make_init_state);
struct State *st = re->state; // Récupération de l'état
// ...
}
Un des choix arbitraires pris ici, est l’argument qu’on donne à la fonction
use_state. Avec React, on donne directement une référence vers l’état
initial, puis on utilise la référence du scope pour le reste de l’exécution. Ce
n’est pas très pratique pour un modèle de mémoire sans garbage collector. Le
choix de passer une fonction d’initialisation, malgré les contraintes du
langage, reste arbitraire. J’imagine sans mal qu’il y ai de nombreuses
implémentations alternatives. Certaines me viennent à l’esprit en écrivant ces
lignes. Bien que celle-ci ne constitue pas un défaut majeur.
Vous avez peut-être remarqué une autre différence avec React qu’implique cette
implémentation. En utilisant le framework javascript, appeler la méthode
dispatch (qui permet de mettre à jour l’état) avec le même objet ne
re-demande pas l’exécution du composant, même si cet objet a été modifié. Dans
le cas ci-dessus, si on gardait la même logique le pointeur pour l’état initial
ne pourrait pas être celui des états suivants. Donc ma bibliothèque est forcée
d’accepter tout appel à dispatch sans vérifier la consistence ou l’égalité
des états.
Je recommande tout de même de ne pas réutiliser l’état précédent dans la fonction de dispatch sans maîtriser ce que vous faites. Le mieux serait de pouvoir utiliser une variable statique par état. La raison pour laquelle il n’est pas conseillé de garder l’état précédent, est qu’il peut être modifié par d’autres parties de l’application avant que la fonction de dispatch n’ait été exécutée ou pendant son transit dans la file d’évènements. Dans ce cas, des data races peuvent entraîner des erreurs difficiles à déboguer.
Quelques chapitres au-dessus, on a vu comment des fonctions de réduction sont enfilées. J’ai précisé ensuite que ces fonctions sont exécutées séquentiellement et leur impacte.
struct Reagir *re = new_reagir(pthread_self()); // L1
while (state_machine()) // L2
{
re->i = 0; // L3
struct Entry e = receive_state(re); // L4
void *new_state = e.rea->reducer(e.rea->pub.state, e.arg); // L5
opt.on_state_change(&e.rea->pub.state, &new_state); // L6
}
Dans l’implémentation de la boucle d’exécution, vous remarquerez qu’il n’y a aucun nettoyage des états précédents. Dans un langage qui n’est pas garbage collecté, c’est un peu problématique. À la place, la bibliothèque appelle une fonction paramétrable, qui permet pour nous de résoudre plusieurs problèmes, dont deux que je souhaite vous exposer.
Premier problème : que se passe-t-il si je souhaite utiliser des états alloués
sur ma heap ? Si c’est le cas, il faut trouver le juste moment où on possède
encore l’adresse de l’état précédent afin de libérer cet espace mémoire. Une
des possibilités qui n’embête pas trop l’utilisateur de la bibliothèque est
celle-ci: on_state_change s’occupera de nettoyer. C’est simple et efficace, à
la création de la machine à états, on donne en paramètre une fonction.
void on_change_with_free(void **dst, void **src)
{
free(*dst);
*dst = *src;
}
void main(void)
{
struct Opt opt = {on_change_with_free};
create(state_machine, &opt);
}
La proposition précédente fonctionne parfaitement dans un contexte synchrone. Si, à tout moment de l’exécution, plusieurs threads pouvaient utiliser ces états créés, dans ce cas, ce bout de code est très très critique. Cependant, il existe des situations où les exécutions seront toujours concurrentes, jamais parallèles, et où ce code fonctionne en l’état. Mais cela n’est pas très générique, ce qui nous amène au second problème.
Second problème : imaginons que pendant la réception d’une nouvelle information la machine à états passe de l’état “A” à “B”. L’exécution vient de passer la ligne L5 (voir la figure de la boucle) et est en train d’entrer dans la fonction de réduction. Si un autre thread modifie “A” à ce moment-là, la fonction de réduction et cet autre thread auront un data race. Au mieux, l’état ne passera pas à B, mais la fonction de réduction ne peut pas avoir de comportement défini.
Pour se protéger, la solution la moins évidente à réaliser, est de faire en
sorte que le programme soit au choix résilient ou qu’il y ait un consensus
entre les threads. L’utilisation de structures non-bloquantes, encore, permet
d’éviter des data races. La fonction de réduction pourrait tenter de
remplacer l’ancien état avec un compare_and_swap élaboré, et essayer de
nouveau tant que l’opération échoue. Dans ce cas, il faut aussi se protéger
contre des libérations de mémoire inattendues. L’accès à une structure, aussi
atomique soit-elle, ne protège pas contre l’apparition d’un pointeur nul comme
référence.
Une manière plus simple de se protéger est l’utilisation de verrous. En combinant une fonction de réduction qui enclenche un verrou et la fonction de nettoyage pour le relacher, on peut réussir à protéger l’état contre des comportements indéfinis. Le verrou peut être contenu dans la machine à état. Dans toutes les circonstances, il n’y a toujours qu’un état courant, donc l’utilisation d’un verrou global est largement suffisante.
void *locker(void *_, void *new_state)
{
lock(&state_mutex);
return new_state;
}
void my_on_state_change(void **dst, void **src)
{
free(*dst); // dans le cas où j'utilise la heap.
*dst = *src;
unlock(&state_mutex);
}
struct Reagir* state_machine()
{
struct Reagir *re = use_reducer(
locker,
initializer
);
return re;
}
Chapitre 7 - Une file plus rapide
Admettons que la situation nous impose d’optimiser la lecture et l’écriture de la file. Effectivement, la structure mpsc implique un goulot d’étranglement. Admettons qu’utiliser un simple verrou sur la file de la machine à états ne suffise pas car utiliser des mutexes coûte au CPU un temps trop précieux pour nous.
Une file est une structure de données qui en théorie n’a pas de taille précise
et qui implémente au moins deux fonctions: pop et push (défiler et enfiler)
et dont les éléments qui entrent et sortent respectent l’ordre FIFO. Avant de
commencer à présenter différentes façons d’optimiser cette structure, regardons
ce que font ces deux routines lorsqu’elles sont synchrones.
Push, par exemple va:
- Créer un nouveau noeud.
- Trouver la fin de la file.
- Relier la fin de la file avec le nouveau noeud d’une quelconque manière.
- Modifier le pointeur de fin de file avec le nouveau noeud.
Pop:
- Trouver la tête de la file.
- Trouver l’élément suivant.
- Échanger le pointeur de en tête de file avec l’élément suivant.
- Supprimer l’ancien noeud.
Les pointeurs de tête et de fin sont initialisés avec un noeud vide qu’on
appellera des dummies, ils serviront essentiellement à combler le début et la
fin de la file et peuvent être, ou doivent être (selon l’implémentation), égaux
et occuper la même zone mémoire. Plus important, la plupart de ces opérations
sont invalides dans un contexte de partage de données entre plusieurs threads
parallèles.
Avant de continuer ce chapitre, il semble nécessaire de savoir reconnaitre si une structure de données, ou plus généralement un algorithme qui produira des effets, est thread-safe ou non. Dans un système concurrent, composé de plusieurs processus et incluant du parallélisme, j’appellerai “thread-safe” un algorithme avec une sémantique synchrone qui gardera cette même sémantique dans tout les scénarios possibles d’appels asynchrones. Parmi les effets indésirables d’un tel algorithme, on peut identifier les désynchronisations, les pertes de données, les fuites de mémoire et tout type de comportements imprévisibles, à condition bien sûr que ces effets ne soient pas souhaités dans la sémantique originale.
Toutefois, s’il est plus ou moins facile de montrer qu’un algorithme ne remplit pas les conditions pour être thread-safe il est difficile de prouver le contraire sans le matériel adapté. Heureusement, il existe quelques langages spécifiques qui permettent de vérifier la conformité d’un algorithme par rapport à ses spécifications. Cependant, excluant le fait que je ne les maîtrise pas, il serait surérogatoire de les présenter ici.
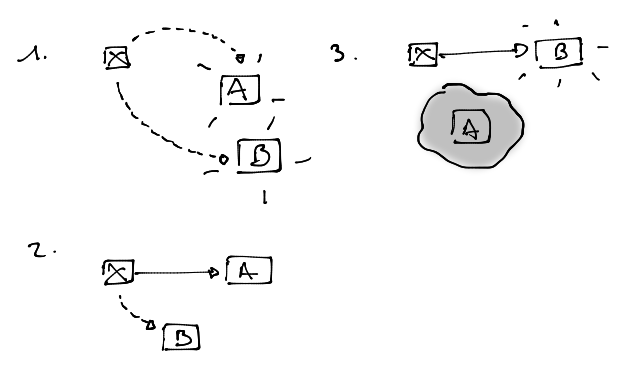
La figure ci-dessus montre un des nombreux scénarios de désynchronisation qui pourraient arriver. En fait, en utilisant cette structure non protégée, ça ne se passera quasiment jamais bien. Si on reste dans des exécutions concurrentes, dans des green threads, pourquoi pas. Mais en incluant du parallélisme, il y a un fort risque de perte de données et de comportement indéfini. Dans ce cas, la solution la plus évidente est d’ajouter un mutex autour de la file partagée. Des solutions plus performantes entrent alors en scène.
L’étape suivante d’une structure de données thread-safe, après le grand mutex, c’est le status non-bloquant ou lock-free. Quand on parle d’algorithmes lock-free, on l’a vu, on veut dire que l’appel d’une routine comme Push garantira que des appels parallèles à Push et Pop pourront se terminer à une ou plusieurs étapes l’exécution. Autrement dit, on arrive à s’organiser entre threads de façon à se partager la structure de données sans se marcher sur les pieds. Précisons tout de même qu’on utilise l’expression se terminer (sous-entendu avec succès) sans la suite logique et avoir fait effet, car ce sont deux concepts distincts qu’on différencie entre parallélisation et linéarisabilité que j’évoquerai plus tard. Je distingue par la suite les termes lock-free et non bloquant, car il est possible d’obtenir dans plusieurs cas des accès parallèles de lecture et écriture à une même structure avec l’utilisation de mutexes.
Pour l’implémentation d’une file adaptée à divers systèmes de producteurs et
consommateurs, on peut utiliser une version synchrone de l’algorithme. Elle ne
sera pas lock-free mais non-bloquante. Elle ressemble à ce qu’on a vu
précédemment dans send_state et receive_state. Sauf qu’on différenciera le
mutex de tête de file et celui de fin de file. Un producteur et un consommateur
ne se bloqueront jamais l’un l’autre. Cependant, on utilise deux verrous, ce
qui signifie qu’on ne peut pas appeler cette structure lock-free. Ici, on
décrit un algorithme qui garantit qu’au moins un thread peut continuer à
s’exécuter pendant que d’autres threads sont bloqués. Un consommateur peut
s’exécuter même si un producteur bloque la file. Par contre, plusieurs
producteurs n’auront pas d’accès simultanés. Cette stratégie s’appelle
“livelock-free”, utilise des mutexes et peut supporter des accès concurrents
dans un context mpmc, mais elle reste limitée en terme de parallélisation.
void enqueue(queue_t *queue) {
node_t *node = (node_t *) malloc(sizeof(node_t)); // E1
pthread_mutex_lock(&queue->tail_lock); // E2
queue->tail->next = node; // E3
queue->tail = node; // E4
pthread_mutex_unlock(&q->tail_lock); // E5
}
void dequeue(queue_t *queue) {
pthread_mutex_lock(&queue->head_lock); // D1
node_t *node = queue->head; // D2
node_t *new_head = node->next; // D3
if (new_head == NULL) // D4
return pthread_mutex_unlock(&q->head_lock); // D5
queue->head = new_head; // D6
pthread_mutex_unlock(&queue->head_lock); // D7
free(node); // D8
}
Étant donné que mon implémentation ne possède qu’un seul consommateur, le verrou
head_lock ne sera pas necessaire. Les lignes D1, et D7 sont optionnelles.
À noter, si on retire les verrouillages et déverrouillages dans la figure ci-dessus, on obtient strictement l’algorithme synchrone de file. Les étapes 2, 3 et 4 d’ajout dans la file sont condensés en E3 et E4. Puis pour le défilement, les lignes D2, D3 et D6 s’occupent des étapes 2 et 3 de l’algorithme. J’ajouterai en commentaire que les lignes E3 et D3 sont des opérations qu’on considère comme atomiques ici. C’est-à-dire qu’elles ne peuvent pas être réalisées strictement en même temps. C’est dans cette direction : reproduire strictement une file synchrone, qu’on devra aller pour trouver un nouvel algorithme libéré des mutexes.
Il faut donc passer le niveau de l’algorithme de obstruction-free à
lock-free. En premier lieu identifions les parties critiques des algorithmes
push et pop. Pour enfiler une valeur, a priori, créer un noeud n’est pas
critique. Trouver la fin de file devient plus difficile. Pour reprendre
l’exemple précédent de choses qui pourraient mal se passer, la fin de file est
susceptible de changer juste avant de passer à la phase 3 ou 4 de l’algorithme.
La récupération de la fin de file, phase 2, n’est pas critique si l’écriture
est conditionnée par le non-changement de la variable, grâce à un Compare
And Swap/Exchange. Dans l’exemple lock-free int c = load(&i); cas(&i,
c, 2);, la partie critique se trouve uniquement dans le compare and
swap, si la valeur de i change entre l’opération de lecture et celle
d’écriture, il est normal de vouloir annuler la modification. Les phases
d’écritures, phase 3 et 4, sont des changements qu’il vaudrait mieux faire sous
condition que la fin de file ainsi que son pointeur next n’aient pas changé.
Plus exactement, si plusieurs threads essaient de modifier la fin de file en
commençant par modifier son pointeur next, utilisez comme simple condition :
le pointeur next est vide, je le modifie si effectivement il est vide
suffis pour résoudre les data races.
let tail = self.tail.load(); // P1
let next = (*tail).next.load(); // P2
if next.is_null() { // P3
if (*tail).next.compare_exchange(next, node) { // P4
self.tail.compare_exchange(tail, node); // P5
return; // P6
}
} else {
self.tail.compare_exchange(tail, next); // P7
}
implémentation en Rust de la file de Mickael & Scott
Cet extrait de la méthode enqueue de mon implémentation en Rust de la file
d’attente non-bloquante, simplifiée pour l’occasion, réalise strictement les
mêmes actions que l’implémentation livelock-free. On trouve les lignes E3 et E5
très ressemblantes à P4 et P5, outre le fait que la condition pour assigner
next et tail est que next n’ai pas changé entre P1 et P4. Tester le
retour de P5 n’est pas nécessaire pour les deux raisons suivantes. Premièrement
deux threads ne peuvent pas valider la condition P4 simultanément.
Deuxièmement, si un thread A valide la condition P4, un second thread B ayant
récupéré une copie de next l’instant d’après, ne validera ni P4 ni P3. Le
thread B tombera dans P7 pour essayer de mettre à jour la fin de file,
exactement comme en P5.
La ligne P7 peut paraître superflue à première vue, elle est le pendant de la ligne P5 qui sera de toute manière executée extrèmement rapidement. Cette ligne, optionnelle en un sens, nous assure cette vitesse de changement de la fin de file ainsi que l’indépendance des threads. Il se pourrait qu’après avoir validé P4, le thread A ayant terminé d’ajouter un noeud, soit “endormi” et laisse temporairement la file dans un état inconsistent. Ce court laps de temps pourrait faire boucler le thread B sur P1, P2 et P3 un certain nombre de fois, ce qui ralentirait le programme. Alors P7 trouve toute son utilité, si A dort, B termine le travail, recommence, et réussi.
Une deuxième implémentation, celle qu’on peut trouver dans les bibliothèques standards modernes, ne se préoccupe pas d’aider les autres threads. La file que je présente n’est pas particulièrement optimisée pour un mpsc. Elle est bien plus générique, elle cherche la performance dans des situations très variées. Le fait de mettre à jour la file en anticipant l’action d’un thread parallèle est une mécanique pessimiste, répétée à la ligne Q7 dans la figure ci-dessous, mais qui dans certains cas peut se révéler indispensable.
let head = self.head.load(); // Q1
let tail = self.tail.load(); // Q2
let next = (*head).next.load(); // Q3
if std::ptr::eq(head, tail) { // Q4
if next.is_null() { // Q5
return None; // Q6
}
self.tail.compare_exchange(tail, next); // Q7
} else {
let ret = (*next).value; // Q8
if self.head.compare_exchange(head, next).is_ok() { // Q9
drop(head); // Q10
return Some(ret); // Q11
}
}
implémentation en Rust de la file de Mickael & Scott
Un algorithme comme celui-ci qui aide les threads à terminer leurs opérations d’écriture, aide forcement la lecture à avancer. Un algorithme écrit en faisant attention à ces détails garantit qu’un thread pourra toujours faire avancer son propre état de façon indépendante et ne restera jamais bloqué par d’autres threads. On dit de ces algorithmes qu’ils sont “linéarisables”.
Veuillez excuser l’emploi du terme technique “linéarisable”, je me propose de vous en offrir une définition concise au sein d’une parenthèse dédiée. Pour commencer, toute routine d’un algorithme a un début et une fin (si la sémantique le demande). Si le début est simple à observer chronologiquement, la fin est souvent moins déterminée. La routine Pop ci-dessus, peut potentiellement finir à Q11, pour cela, elle devra préalablement valider la ligne Q9. En réalité, on peut affirmer que cette routine termine ses effets avec succès lorsque le compare and swap s’exécute correctement, la suite reste du simple utilitaire pratique. Au vu déjà de cet aspect temporel des appels et des retours, nous pouvons créer un historique tel que : “j’appelle push(A)” puis “A est dans la liste”. Combiné avec la routine Pop nous pourrions observer cette suite d’événements :
- push(A)
- A est dans la liste
- pop()
- pop retourne A
Vous remarquerez que chaque appel d’une fonction est suivi par son résultat, ce qui nous rassure d’un point de vue logique. Pop ne retourne pas de valeur avant son appel, de même, la réponse “A est bien dans la liste” précède strictement le retour de Pop, ceci nous confirme que l’espace-temps dans lequel nous testons notre algorithme est bien linéaire. Autrement dit, nous pouvons raisonner à propos de son exactitude. Un deuxième scénario réaliste pourrait être : Pop ne retourne pas d’information en un laps de temps raisonnable. Comment dans ce cas juger de du déterminisme ainsi que de la linéarité de l’historique sémantique ? Pop finira-t-il un jour ? En fin de compte, un algorithme linéarisable doit respecter certaines contraintes temporelles. Il faudrait, entre autres, qu’un appel à une de ces routines donne l’impression de se terminer instantanément après son appel. Or, “donner l’impréssion de” implique une vision subjective et complexe à déterminer pour la plupart des algorithmes. Ceci nous amènerai à des réflexions trop eloignées du périmètre de l’informatique. Une seconde définition équivalente, plus simple à prouver, est la suivante : entre le début de la routine et sa fin, il doit exister une ou plusieurs étapes où la routine a fait effet. Pour Pop, par exemple Q9 peut être cette ligne à condition qu’une de ces itérations lui permette de faire réussir l’échange. Q9 est ici le point de linéarisation de la routine. Vous l’aurez compris, ces contraintes sont primordiales pour pouvoir raisonner correctement à propos d’un algorithme, et éviter des incohérences dans de nombreux contextes. Concluons cette parenthèse en dépit du fait qu’il subsiste encore un abondant corpus de réflexions à opérer sur ce thème.
Reprenons l’implémentation du mpsc. Comme avec l’algorithme livelock-free présenté précédemment, il n’est pas nécessaire d’utiliser de variable atomique pour le pointeur vers la tête de file. Si le cas d’usage nous garantit qu’un unique thread pourra accéder à cette fonction, pas nécessairement le même thread à chaque appel, la ligne Q9 peut être remplacée sans hésiter par une écriture tout ce qu’il y a de plus banale. Dans le cas générique, ce mécanisme protège les consommateurs de plusieurs scénarios de duplication de données et de data races. Il protège entre autres des doubles libérations de mémoire, on peut libérer la mémoire de l’ancien noeud sans crainte dans cet algorithme car l’échange en Q9 ne peut se faire que par un seul thread. Après l’échange de head et next, la head précédente est inaccessible à tout autres threads. Avec certitude, on ne déréférencera jamais un pointeur nul et on ne cherchera pas non plus à libérer sa mémoire deux fois.
Les deux extraits de code précédent sont tirés d’une version d’implémentation d’une Michael & Scott Queue. L’algorithme en question corrige normalement le problème appelé ABA. Cette partie n’est pas présentée ici, notez cependant que dans un algorithme linéarisable, la plupart, pour ne pas dire tous, résolvent l’ABA en utilisant un compteur pour vérifier la consistance entre les noeuds. Chaque noeud aura un identifiant unique en plus d’une adresse et d’un contenu, évitant les confusions.
L’implémentation de la bibliothèque standard de Rust a évolué pendant que j’écrivais ces lignes. Aujourd’hui l’implémentation de mpsc / mpmc ressemblerait plus à une Mickael & Scott Queue comme si dessus avec quelques améliorations pour la partie unbounded et est resté sur une proposition de Dmitry Vyukov’s pour la partie bounded. N’ayant pas d’autres informations pour le moment, je reserve plus de détails dans des chapitres ultérieurs.
Si vous développez en Rust, l’implémentation dans la bibliothèque standard respecte les critères d’une file lock-free non intrusive de multiples producteurs et unique consommateur. Dans le pseudocode suivant, si un producteur p1 exécute R1 et R2, puis un producteur p2 exécute R1, R2 et R3, puis p1 termine la routine avec R3, en considérent les paragraphes et exemples précédents, pensez vous que cet algorithme est linéarisable ? Pourquoi ne peut-il pas y avoir d’ABA avec cette méthode ?
fn create():
self.tail = self.head = dummy_ptr;
fn push():
let node = Node::new(); // R1
let prev = self.next.swap(node); // R2
prev->next.store(node); // R3
fn pop():
let tail = *self.tail.get(); // S1
let next = tail->next.load(); // S2
if !next.is_null(): // S3
*self.tail.get() = next; // S4
drop(tail); // S5
return Success // S6
if self.head.load() == tail: // S7
return Empty // S8
return WaitingAnInput // S9
Pour conclure ce chapitre, je voudrais attirer l’attention sur les lignes S7, S8 et S9 de la figure précédente. L’implémentation de ce test est tout à fait optionnelle, si le thread consommateur n’a pas encore accès à une information, bien qu’un producteur soit en train d’en ajouter une, la réponse Empty reste acceptable. D’autant plus que dans un thread A qui sera différent du thread du consommateur, l’exécution de R1 peut potentiellement commencer lorsque S7 est validé, alors l’inconsistance de la file ne sera pas détectée. Nous pouvons penser que l’usage d’une file par rapport à une autre a toujours une raison valable, qu’un algorithme ne peut pas varier sous peine d’un danger imminent de comportement indéfini. Pour le moment, il a été démontré le contraire. Dans certains cas, on peut retirer des verrous ou des accès atomiques et tout ira bien. Certains préféreront un algorithme linéarisable, mais tout est une question de contexte, d’opinion, de dosage, d’évaluation de risque, c’est pourquoi une implémentation qui est plus rapide dans 99% des cas et extrêmement coûteux dans le dernier a sa place dans une bibliothèque standard. C’est pourquoi on peut aussi espérer détecter une inconsistance (S7-S9), car dans ce cas, on sait comment réagir au mieux et améliorer, du fait, une vitesse moyenne d’exécution.
Chapitre 8 - Machine à états industrielle
Il peut arriver qu’une machine à états soit nécessaire dans votre programme car pour communiquer correctement avec des composants embarqués. Il se peut également que les événements reçus de ces composants soient invalides, arrivent à des moments imprévus, se répètent plusieurs fois, ou ne soient pas dans l’ordre attendu.
En utilisant la bibliothèque Reagir, définissons une machine à états un peu plus réaliste. Cette fois-ci, la lecture de l’entrée utilisateur est parallèle à l’exécution, donc on peut recevoir des événements à tout moment. Nous ne pouvons pas garantir que les composants du système nous enverrons des signaux lisibles ou cohérents. L’automate ressemble à ceci :
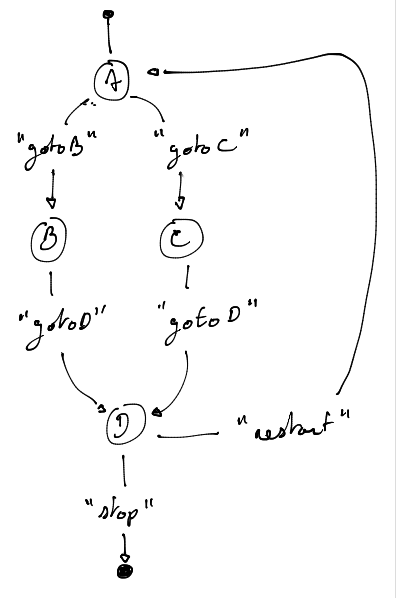
Le code doit être clair et précis. Il est important de noter que dans le milieu industriel, les machines à états évoluent souvent plus rapidement que le reste du programme, il est donc essentiel de maintenir un code facile à modifier. Par rapport à l’exemple précédent, la fonction state_machine ne varie presque pas. La structure de l’état ne devrait contenir que les fonctions d’étapes qui produisent les effets de bord, ainsi que les éléments nécessaires à l’application, comme le contexte. Les fonctions, dans l’exemple suivant, toujours appelées de dynamiquement, définissent également pour l’état courant les événements attendus.
State_t state_A = {fn_state_A};
// [...]
State_t state_E = {fn_state_E};
void fn_state_A(State_t *_) {
onEvent("gotoB", &state_B);
onEvent("gotoC", &state_C);
}
void fn_state_B(State_t *_) {
onEvent("gotoD", &state_D);
}
void fn_state_C(State_t *_) {
onEvent("gotoD", &state_D);
}
void fn_state_D(State_t *_) {
onEvent("restart", &state_A);
onEvent("stop", &state_E);
}
Lorsque le programme entre dans l’état A, il execute la fonction associée
fn_state_A. Laquelle, à part les effets de bord qu’elle implique, peut
définir quelque part que la machine s’attend à présent à un des évenements
gotoB et gotoC et aucun autre. Le signal d’un de ces évenements entrainera
respectivement le passage à l’état B ou C. Il est important de remarquer les
avantages de décrire sa machine à états de cette manière : elle est extrèmement
fléxible et lisible. Avec cette technique de base, il est possible d’écrire des
programmes d’une étonnante compléxité.
En ce qui concerne la communication avec d’autres composants, il est
important de noter que chaque état peut recevoir un ou plusieurs événements, dû
à du bruit ou à un mauvais traitement du signal dans une partie plus bas
niveau. Dans notre exemple, nous recevons du texte, mais cela pourrait être
n’importe quel signal externe ou interne. Admettons que nous soyons en train de
communiquer avec des composants qui fonctionnent en temps réel, et qu’un
message tel que gotoB puisse être reçu plusieurs fois avant que la partie
matérielle responsable ne se mette à jour. Pour gérer ces cas, il est judicieux
de centraliser les changements d’état en utilisant une fonction de réduction.
Une fonction de réduction donne la possibilité de définir les mises à jour de l’état en fonction de l’état actuel et d’un nouvel évènement. Elle est appelée en amont de l’exécution d’un état et peut décider si valider ou non une transition. L’état suivant est définit par la valeur de retour de la fonction de réduction. Si cette valeur est nulle, la bibliothèque ignorera l’évènement. Cette fonction permet surtout de centraliser les transitions, vous pouvez rendre votre code plus lisible et maintenable en séparant clairement les différentes actions qui peuvent modifier l’état de votre application.
void *find_next_state(void *old_state, unsigned char *event)
{
static char previous_event[30] = {'\0'};
if (strcmp(previous_event, (char *)event) == 0) // P1
return NULL;
void *state = hashmap[hash(event)];
if (state != NULL) // P2
memcpy(previous_event, event, 30);
return state;
}
void *reducer(void *old_state, void *event)
{
void *ret = find_next_state(old_state, (unsigned char *) event);
free(event);
return ret;
}
Dans la figure précédente, la ligne P1 protège contre des signaux dupliqués. On
ne peut recevoir un signal qu’une seule fois, sa répétition est interdite.
Notez qu’en pratique, vous pourriez souhaiter ajouter quelques exceptions à
cette règle. Par exemple, il est possible que vous vouliez recevoir un signal
next plusieurs fois. Pensez alors à ajouter des fonctions de vérification. Ce
problème est très similaire à un autre dont il faut tenir compte avec de la
programmation atomique, ce qui relie enfin concrètement nos deux thématiques.
Regardez la figure Rust ci-dessous, ce morceau de code modifie la valeur du
paramètre et signal en modifiant un flag qu’elle a été modifiée, comme pour le
spinlock vu précédemment. En C ou C++, on n’aurait même pas besoin de
préciser que ces paramètres sont atomiques, ni qu’elles sont cachées derrière
un compteur de référence. Malgré tout, la particularitée de Rust à être memory
safe n’exempte pas ce code d’un possible data race. Lorsqu’on ne précise pas
l’ordre, ou qu’on donne un ordre Relaxed, à l’écriture de variable, on ne
peut pas confirmer avec certitude que val sera toujours modifié avant
modified_flag. C’est cela que l’on nomme un spurious wake up.
Lorsqu’on ajoute à la place de P1 une exception, on doit toujours y ajouter si nécessaire une protection. En général, une variable tierce, un timestamp ou un identifiant qui nous permettra de vérifier si l’évènement est unique.
fn modify_val(modified_flag: Arc<AtomicBool>, val: Arc<AtomicU32>) {
val.store(42, Relaxed);
modified_flag.store(true, Relaxed);
}
fn read_val(modified_flag: Arc<AtomicBool>, val: Arc<AtomicU32>) {
while modified_flad.load(Relaxed) == false {}
assert_eq!(val.load(Relaxed), 42); // Peut fail
}
Gardons à l’esprit que ce code est exécuté de façon synchrone, ça signifie que
l’état actuel a déjà été appliqué. Premièrement, on ne peut pas être
simultanément dans une fonction comme fn_state_A et dans la fonction de
réduction. Deuxièmement, la fonction de réduction est appelée avant que l’état
fasse ses effets. Conclusion, quand on entre dans la fonction de réduction, la
machine à états est abonnée aux seuls évènements attendus dans son contexte
actuel. La ligne P2 nous permet d’ignorer ces évènements inatendus. Si nous
sommes à l’état B, le signal gotoC sera ignoré. Ça peut être un comportement
erroné, dans certains cas, on peut souhaiter que l’état devienne vraiment C
dans la mesure du possible. Si besoin, j’ajouterai un état transitoire qui
tentera d’annuler les effets de bord de l’état précédent.
Représenter son programme grâce à un diagramme d’états et de transition facilite le développement d’applications complexe. On se fait un cadeau en décrivant à haut niveau le fonctionnement de son programme. On peut vérifier l’exactitude, les besoins, transmettre une connaissance rapidement dans une équipe et améliorer la communication entre les composants.
Chapitre 9 - Le problème du dernier état
Revenons sur la file d’évenement un instant et comment elle est implémentée. Lorsque dans la boucle de la machine à états le consommateur attend un nouvel évènement à traiter, il est préférable de permettre au CPU d’utiliser le coeur inactif durant l’attente. Évidemment, ça dépend des cas, encore une fois.
On souhaite utiliser un file non-bloquante et, dans la mesure du possible, ne
pas invoquer de verrou. Une implémentation similaire à celle de Réagir, qui
utilise des variables conditionnelles, pourrait ressembler à la figure
ci-dessous. La boucle de réception tente dans un premier temps de tirer un
élément de la file, en cas de réussite (R5) il traite l’entrée, en cas d’échec,
il attend une nouvelle entrée et un signal (S2). L’attente en R4 symbolise donc
l’attente d’un signal dans le cas où la file serait vide et push est notre
variable conditionnelle.
send(e):
queue.push(e); // S1
signal(&push) // S2
receiver_loop():
let e = queue.pop(); // R1
if e == Null: // R2
let guard = lock(&mutex); // R3
wait(&push, &mutex); // R4
else:
received(e); // R5
On remarque dans un premier temps qu’on utilise un verrou autour de la variable conditionnelle. Purement pour respecter les bonnes pratiques, celui-ci est optionnel. Au cas où le fonctionnement des cond_var le permettait, on s’en passerait. Mais cette implémentation a un plus gros défaut. Si le consommateur vient d’échouer à lire une entrée, au moment où il entre dans R3, un producteur peut entrer en action, terminer S1 et S2, avant que R4 ne soit invoqué par le consommateur, le laissant alors dans un état de veille avec une entrée (ou plus) dans la file. En fait, le problème est d’informer au thread du consommateur de ne pas se mettre en veille entre R2 et R4, ce qui est impossible sans d’autres mécanismes de synchronisation.
La première technique, si je choisis de continuer avec des variables conditionnelles et des verrous, utilise le concepte de sémaphore. Or, si je persiste, je finis dans tous les cas dans une file synchrone où, au mieux, quelques threads pourront être parallélisés avec difficulté. La deuxième méthode, la plus moderne, utilise des futex. Dans ces chapitres, je n’ai pas présenté le fonctionnement des variables conditionnelles, ni même des mutexes. Je ne vais pas non plus entrer dans les détails des futex, mais les exemples qui suivront permettront sûrement d’éclaircir cet aspect de l’informatique pour ceux qui n’ont jamais fait l’expérience de ce mécanisme de synchronisation.
Prenons n’importe quelle file lock-free qu’on peut trouver, que ça soit celle de la bibliothèque standard Rust ou bien une plus générique et linéarisable. Nous savons que le retour de la routine pop peut être nul, même si un producteur vient d’être appelé. Dans la file mpsc de Rust, on peut avec un peu de chance identifier cet état d’inconsistence, il semble que dans ce cas précis, boucler sur la routine pop jusqu’à recevoir de la donnée soit une bonne chose à faire. Dans l’autre cas, autant plus probable, il faut savoir gérer le status de la structure mpsc en ne sachant rien des activités des threads parallèles.
Utiliser des futexes dans cette situation est approprié. En quelques mots, ce mécanisme permet de créer un verrou si une variable atomique remplit une condition. Exactement comme pour le compare and swap , où l’objectif serait d’enclencher l’attente d’un signal. La figure ci-dessous ressemble plus ou moins à ce qu’on pourrait réaliser avec des sémaphores de façon plus moderne. De plus, l’utilisation de swap qui retourne l’état précédent et de fetch_sub qui passera selon les cas du status Notified à Running et de Running à Waiting, fait que cette partie de l’implémentation est wait-free. Cette méthode est aussi connue sous le nom de “thread parker”, le consommateur attend jusqu’à ce qu’il soit notifié, à condition de ne pas déjà être notifié.
Notez également deux points. Premièrement, la boucle B5, celle-ci protège d’un possible spurious wake up, qu’on a déjà décrit, de la part du système, détécté par le test B7. Deuxièmement, ce n’est pas évident dans le pseudocode qui suit, appeler un futex aujourd’hui passe par un appel système, et donc s’avère différent pour chaque architecture.
let Notified = 2, Running = 1, Waiting = 0;
let status = Running;
send(e):
queue.push(e); // A1
if status.swap(Notified) == Waiting: // A2
futex_wake(&status); // A3
receiver_loop():
let e = queue.pop(); // B1
if e == Null: // B2
if status.fetch_sub(1) == Notified: // B3
return; // B4
loop: // B5
futex_wait(&status, Waiting) // B6
if status.cas(Notified, Running): // B7
break; // B8
else:
received(e); // B9
Premier récapitulatif
Malheureusement, je ne suis pas en mesure de formuler une conclusion définitive à propos des machines à états ni de la programmation multithreadé, ce domaine étant en constante évolution (une telle conclusion est probablement irréalisable). Toutefois, je peux avancer quelques observations basées sur mes dernières lectures et conversations.
Au cours de mes investigations, j’ai remarqué des similitudes entre les développements récents et les réflexions exposées par Pierre Boule dans son oeuvre “La planète des singes”. Les travaux publiés entre 1990 et 2010 semblent avoir eu une profonde influence sur la dernière décénie. Une explication plausible est que nous soyons réellement inspirés par les fondateurs de l’informatique, ce qui peut expliquer en partie notre tendance à imiter les développements antérieurs.
Pour ma défense, un développeur expérimenté peut parfois comprendre le fonctionnement d’outils qu’il utilise depuis longtemps, comme un bûcheron qui saisit enfin le fonctionnement de la hache qu’il manie. De plus, il peut être utile de vulgariser certaines connaissances pour les rendre accessibles à un public plus large. Cependant, nous sommes en droit de supposer que la connaissance peut se perdre avant d’être redécouverte de génération en génération. Dans ce cas, nous ferions mieux de lire les premiers travaux pour comprendre les erreurs du passé ainsi que les “nouvelles” techniques de programmation.
En résumé, je vous suggère d’aller plus en détail sur certains points que nous
avons abordés. Pour comprendre les problèmes de linéarisations, vous pouvez
lire les raisons du changement du mpsc de la bibliothèque standard Rust. Pour
les machines à états, vous pouvez explorer leur utilisation dans la
reproductibilité, le calcul à la volée et les algorithmes distribués. Vous
pouvez également lire l’implémentation de la bibliothèque Reagir et
comprendre pourquoi il serait vain de tester chaque entrée dans la routine
dispatch. Vous pouvez imaginer de nouvelles implémentations en C, de
nouvelles représentations et essayer d’autogénérer une machine à état à partir
d’un format BNF. Enfin, vous pouvez prendre de l’avance sur mon prochain
article en proposant des implémentations dans des langages plus modernes et les
comparer avec les méthodes existantes ou en développement.
Comments
Join the discussion for the article on this ticket.